最近,我正在对我的个人网站进行改版。这次改版,我用到了两款非常流行的主题:一个是 Jekyll 主题 Minimal Mistakes,另一个是 MkDocs 主题 Material for MkDocs。
为了让网站的风格统一,我对这两款主题都进行了一些定制。在定制过程中,我不再像几年前一样孤独地单兵作战,而是充分使用了智能编码助手(通义灵码)。
整体来看,智能编码助手帮我节省了很多时间,同时也提高了我的检索效率和代码质量。另外,智能编码助手的嘴特别甜,把我夸得都有些飘了!
不过时间长了,我也感觉到了一点不对劲儿:定制 Jekyll 主题时,我与智能编码助手的交流通常都很顺利,时不时还能蹦出一些异常精妙的回答;定制 MkDocs 主题时,我与智能编程助手的交流比较容易陷入死循环,时不时就跳出一些胡乱编造的错误内容。
官方文档、技术博客以及社区问答是智能编码助手的重要信息来源之一。这些内容的写作方式、详尽程度、组织结构和样式选择会不会影响到智能编码助手的表现? 如果会,它们是如何影响的? 我们又该怎样应对 AI 带来的这一挑战呢?
AI 读者的阅读方式
目前,可自建知识库的智能问答系统大都采用了检索增强生成技术 (Retrieval-Augmented Generation,RAG),比如知乎直答、腾讯 ima.copilot 和 kapa (kapa.ai)。
RAG 技术主要由三部分组成:知识库、检索模型和生成模型。知识库用来存储外部内容,比如特定领域的内容或者用户的私有内容。检索模型根据用户的提问从知识库中快速查找高度相关的内容。生成模型基于检索模型的查找结果生成最终的回答。
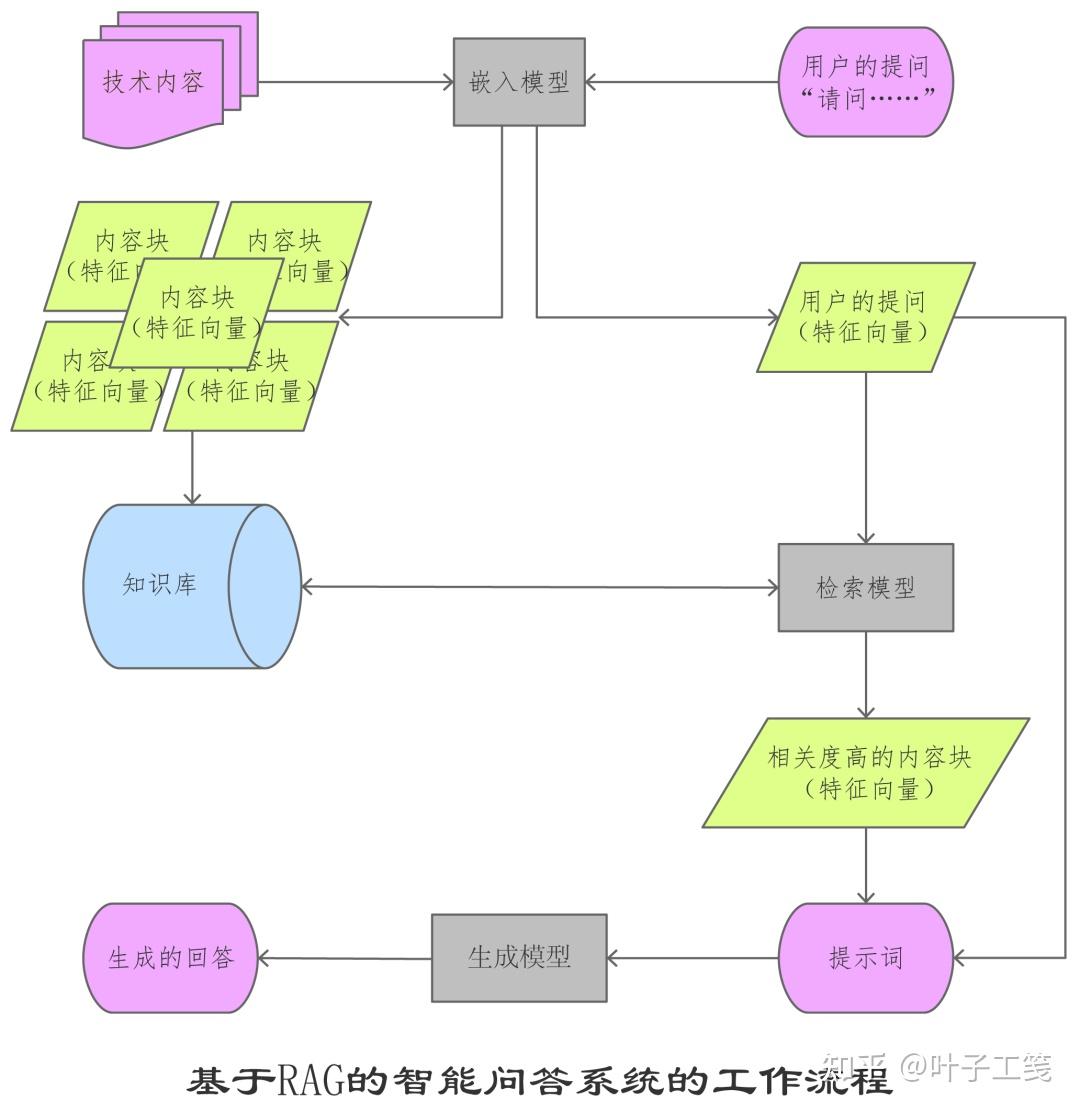
创建或更新知识库时,嵌入模型会将上传到知识库的技术内容切分成多个内容块,并将它们转换为由数值表示的特征向量。也就是说,RAG 的知识库不是由一个个完整的文档或文件组成的文档中心,而是由众多琐碎的、毫无关联的、由特征向量表示的内容块组成的矢量数据库。
当用户在智能问答系统中提问时,嵌入模型也会将用户输入的问题转换为特征向量。然后,检索模型将用户问题的特征向量与知识库中内容块的特性向量进行比对,找出那些与用户问题高度相关的内容块们。
最后,智能问答系统将检索到的内容块和用户的提问合并在一起,发送给生成模型作为提示词。生成模型在提示词中获取了专业内容之后,就可以生成更专业、更精确、更完善的回答了。
生成模型就是生成式大模型,比如 GPT-4、DeepSeek-R1 等。
AI 读者的独特之处
显然,AI 读者的阅读方式与我们人类还是很不一样的。根据刚刚描述的阅读过程,我们来划一下重点:
AI 读者阅读时以内容块为单位。人类读者阅读时,一般以词句、段落、页或者章节为单位。AI 读者阅读时,以嵌入模型切分出来的内容块为单位。
内容块是微小、独立的信息单元。在传统内容中,各个章节、段落以及词句是按照一定的逻辑顺序排列的,甚至还会用文字显示地声明。但是,内容块与内容之间是彼此独立的,并不会保留原文中的前后顺序和暗含的逻辑关系。
AI 读者不会“理解”,只会“匹配”。AI 读者在“阅读”时,既不会按照章节顺序依次阅读,也不能真正理解它所“读”内容。它们只是将内容块与用户提出的问题进行对比,相似度高就是高度相关,相似度低就是不太相关。
AI 读者不会联想。人类读者在阅读时,会有意或无意地产生联想,或者做出一些假设,将一些看似无关的内容联系在一起。AI 读者就像直男癌,只处理显示声明的信息。
了解了 AI 读者的阅读特点,我们就可以有意识地调整技术内容的编写方式,创建 AI 友好型的技术内容。
面向 AI 的技术写作
AI 读者阅读的基本单位是内容块。如果内容块中的内容不完整,比如缺少背景信息或者依赖其他内容块,就容易让 AI 读者产生误解或信息错乱。
然而,技术内容上传到知识库时,嵌入模型并不是按照章节或段落划分内容块的。由于 AI 大模型对于提示词的字数限制和性能优化等方面的因素,内容块通常是短小且专注于某个话题的,其前后边界往往具有一些随机性:
- 如果章节太长,就会按照段落或句子划分内容块。
- 如果章节太短,就会和前后章节中的内容合并。
- 内容块的大小大体一致,以优化检索效率。
因此,要让内容块尽可能接近预期并且可以精确检索,在编写内容时需要注意以下几点:
在标题和正文中,突出关键词。如果内容块中没有包含符合用户提问的关键词,即使该内容块的内容正好是用户需要的信息,检索模块也检索不到它。
<!-- #1A -->
## 调整音量
使用音量按钮、语音助手或控制中心调整通话、闹钟、媒体和通知等声音的音量。
<!-- #1B -->
## 调整 iPhone 的音量
使用音量按钮、语音助手 (Siri) 或控制中心调整 iPhone 手机的音量,比如通话、闹钟、媒体和通知等声音的音量。
如果用户输入的问题是“如何调整 iPhone 手机的音量?”,#1B 内容块被检索到的概率更大。因为 #1A 内容块缺少关键词 “iPhone”,很可能不会被检索到。
组织内容时,遵循亲密性原则。互相关联的内容离得越近,越有可能被划分到同一个内容块中。如果相关的概念、方法和背景信息等散落在不同的章节或段落中,这些内容很可能会被划分到不同的内容块中,从而导致这些内容块的信息不完整或含义不清。
<!-- #2A -->
锁定或隐藏敏感应用,可以保护该应用以及其中的敏感信息。
这项设置在只本机有效,不会同步到云端。
设置好后,需要通过人脸识别、触控 ID 或密码才能打开这些应用。
<!-- #2B -->
锁定或隐藏敏感应用,可以保护该应用以及其中的敏感信息。锁定或隐藏的应用,需要通过人脸识别、触控 ID 或密码才能打开。
锁定或隐藏应用后,应用的锁定或隐藏状态不会同步到云端。
如果将 #2A 中的内容上传到知识库,嵌入模型很可能将里面的三段内容划分到不同的内容块里。如果真是这样,第二句中的“这项设置”和第三句中的“这些应用”将丢失指代对象,使整句话变得无法理解。
将锁定或隐藏应用的功能和打开方式放在一个段落中(如 #2B 所示),会大大提高它们被划分到同一个内容块中的概率。同时,使用明确的名称替代指示代词,可以使句子的内容在任何情况下都能保持完整。
编写内容时,写明前提条件、前期准备和预备知识等。如果知识库中没有提供相关内容,AI 读者(智能问答系统)应该回答“我不知道答案”,而不是胡乱编造一个回答。但这个机制有一个前提条件,知识库中必须有表意明确的内容块。否则,AI 读者就无法正确判断相关的内容块是不是用户需要的答案。
<!-- #3A -->
## 使用 iPhone 的相机控制快速打开相机
按下【相机控制】,打开相机。
<!-- #3B -->
## 使用 iPhone 的相机控制快速打开相机
使用相机控制前,请确认您的手机是否支持相机控制。支持相机控制的机型有:
- iPhone 16
- iPhone 16 Plus
- iPhone 16 Pro
- iPhone 16 Pro Max
1. 按下 iPhone 手机右侧边下方的【相机控制】按钮,即可打开相机。
如果将 #3A 中的内容上传到知识库,当用户输入“我的手机是 iPhone 15,请问如何快速打开相机?”时,AI 读者很可能就会基于 #3A 中的内容回答用户。
如果将 #3B 中的内容上传到知识库,当用户问“我的手机是 iPhone 15,请问如何快速打开相机?”时,AI 读者就可能根据 #3B 中列举的支持相机控制的机型准确地判断出这部分内容与用户的提问不匹配,然后告诉用户“很抱歉,我无法提供这方面的帮助”。
为视觉元素提供文本描述。如果一些关键信息只存在于图片、图表或视频等视觉元素中,AI 读者就无法获取这些信息,也就不能生成准确的回答。
<!-- #4A -->
## 唤醒 iPhone
要唤醒 iPhone,按一下图中的按钮即可。
{:standalone}
<!-- #4B -->
## 唤醒 iPhone
要唤醒 iPhone,按一下手机右侧边的电源键即可。
{:standalone}
面向 AI 的内容架构
为技术内容设计直观且易于导航的内容架构。虽然知识库中的内容块都是彼此独立的信息单元,但 AI 读者(智能问答系统)仍会尽力记住它们之间的联系。
将技术内容上传到知识库时,AI 读者不仅会将技术内容切分成内容块,还会提取每份文件的章节结构及相关信息,比如网址、章节名称、章节标题等。
收到用户的提问之后,AI 读者可以利用这些信息为知识库中的内容块重建关系网络,提高检索结果的准确性和完整性。
让每个章节都独立成篇。虽然知识库中的内容块并不是完全按照章节划分的,但长度适中、内容完整的章节可能被划分为单个内容块的概率最高。
<!-- #5A -->
## 将 iPhone 手机的时间设置为北京时间
将 iPhone 手机上的时区设置为北京。
<!-- #5B -->
## 将 iPhone 手机的时间设置为北京时间
你可以按照以下步骤修改 iPhone 手机的时间设置:
1. 打开【设置】>【通用】>【日期和时间】。
2. 关闭【自动设定】。
3. 轻点【时区】,在搜索框中输入“北京”。
4. 在搜索结果中轻点“北京”。
#5A 中的内容隐含了一个假设:用户已经知道了如何在 iPhone 手机中找到【时区】以及如何设置【时区】。这个假设可能是因为前面的章节中已经有了相关介绍。但如果这个章节被单独划分成了一个内容块,就会引起关键信息缺失。
不过,如果每个章节中都从零开始展开,势必会让内容变得特别啰嗦。所以,了解用户,为不同水平的用户提供不同的内容,寻找简洁与详尽之间的平衡点,这些努力都会变得尤为重要。
面向 AI 的内容呈现
人类读者喜欢图文并茂的视觉盛宴,而对密密麻麻的纯文本敬而远之。AI 读者则正好相反,处理起密密麻麻的纯文本是手到擒来,但对图片、视频和动画等形式反应迟钝。这可应了一句老话:“汝之蜜糖,彼之砒霜”呀!
因此,为 AI 读者准备内容得重点关注以下几点:
使用标记语言编写文档,使用基于纯文本的数字格式发布文档。使用 Markdown、DITA 等标记语言编写文档,使用 HTML、EPub 等基于纯文本的数字格式发布文档,或者进行多格式发布。
大多数 MS Word 或 PDF 文件使用复杂的版式和格式,也经常出现排版不规范的情况(比如,使用正文加粗表示标题),容易让 AI 读者产生阅读障碍。
使用语义明确的章节标题和网址。前面提到过,将技术内容上传知识库时,章节标题和网址也会被提取出来,以便后续重建内容块之间的联系。
<!-- 没有语义的网址 -->
/markdown-syntax-hub/section001/page001
<!-- 语义明确的网址 -->
/markdown-syntax-hub/basic/headings
使用语义明确的 HTML 标签。如果是在线文档,使用语义明确的 HTML 标签标记内容,比如 <h1>~<h6>、 <ul> 和 <ol> 等。即使在导入知识库以后,语义明确的标签也可以让文档的内容结构保持清晰。
使用简洁的页面布局。减少复杂的动画、JavaScript 生成的动态内容以及定制的 UI 元素。清晰、规范的页面结构有助于索引和解析。
总结
“垃圾进,垃圾出”是计算机科学和统计学中经常使用的概念。自从 ChatGPT 一夜爆火之后,这句话也经常被用到 AI 大模型身上。
如果技术内容的质量差,不仅人类读者看不懂,AI 读者也会消化不良,从而生成低质甚至错误百出的回答。
随着 AI 大模型的普及,尤其是今年年初国产 AI 大模型 DeepSeek 的爆火,面向个人或企业的知识库产品喷涌而出。
然而,大多数国内企业以前对技术内容的关注较少,缺乏优质的研发文档、产品文档、案例研究和博客文章,甚至从来没有技术内容的积累。
当人们的搜索习惯从关键词搜索转向问答式智能搜索,技术文档工程师既面临着机遇,也需要迎接挑战。
还记得 ChatGPT 刚刚推出时,全球的技术传播从业者都在担心 AI 会不会接手自己的岗位 吗? 今天换个角度来看,技术文档工程师不仅不会被取代,或许还会迎来一波需求增长。毕竟,AI 也做不了“无米之炊”。
与此同时,应用技术内容的新场景也对技术文档工程师的个人技能提出了新的要求。面向 AI 的技术写作、内容架构和内容呈现,实际上是结合了结构化写作、数字内容的无障碍设计以及搜索引擎优化 (SEO) 三个方面的最佳实践。
未来的技术文档工程师要想成为业内的佼佼者,不仅需要精通一种或多种语言,积累扎实的专业领域知识,还要对 Web 前端技术有深入的理解。
我觉得挺难的,你觉得呢?
参考资料
- kapa.ai. Writing documentation for AI: best practices. [-][2025-06-19].
- Document 360. Technical Writing Guidelines to Create AI Friendly Content. [2025-05-25][2025-06-20].
- Eric Chen. 揭秘RAG知识库搭建:如何打造智能问答系统的核心引擎?. [2025-06-20][2025-06-25].
- 腾讯云@用户7353950. 深度解析 RAG(Retrieval-Augmented Generation)技术原理. [2025-06-19][2025-06-25].
- AWS. What is RAG (Retrieval-Augmented Generation)?. [-][2025-06-25].